
Content
Table of Contents
Common functions
//Use make to create a slice
func make([]T, len, cap) []T
//Copy function, copy src to dst
func copy(dst, src []T) int
//Add elements to the end of the slice
func append(s []T, x ...T) []T
Data structure
Array
The size of a Go language array cannot be changed after initialization. Array types that store the same element type but different sizes are completely different in the Go language. Only when both conditions are the same can they be the same type.
- Initialization
There are two different ways to create arrays in Go. One is to explicitly specify the array size, and the other is to use [...]T to declare the array. Go will infer the array size from the source code during compilation:
arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}
The results of the above two declarations during runtime are exactly the same. The latter declaration will be converted to the former during compilation, which is how the compiler infers the array size.
- Access and assignment
Whether on the stack or in the static storage area, the array is a series of memory space in memory. We represent the array by a pointer to the beginning of the array, the number of elements, and the space occupied by the element type. If we don’t know the number of elements in the array, we may go out of bounds when accessing it; and if we don’t know the size of the element type in the array, we have no way of knowing how many bytes of data should be taken out at a time. No matter which information is lost, we can’t know what data is stored in this continuous memory space:
Slice - Dynamic Array
In Go language, the declaration method of slice type is somewhat similar to that of array, but because the length of the slice is dynamic, you only need to specify the element type in the slice when declaring it:
[]int
[]interface{}
From the definition of slice, we can infer that the type generated by the slice during compilation will only contain the element type in the slice, that is, int or interface{}, etc.
- Initialization
There are three ways to initialize slices in the Go language:
-
Get a part of an array or slice by subscript;
-
Use a literal to initialize a new slice;
-
Use the keyword
maketo create a slice:
arr[0:3] or slice[0:3]
slice := []int{1, 2, 3}
slice := make([]int, 10)
Use subscripts
Using subscripts to create slices is the most primitive and closest to assembly language. It is the most basic of all methods. The compiler will convert statements such as arr[0:3] or slice[0:3] into OpSliceMake operations. We can verify this with the following code:
// ch03/op_slice_make.go
package opslicemake
func newSlice() []int {
arr := [3]int{1, 2, 3} 3}
slice := arr[0:1]
return slice
}
Map hash table
- Initialization
Literal
Current modern programming languages basically support the use of literal initialization hash, generally using the key: value syntax to represent key-value pairs, and Go language is no exception:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
We need to declare the type of key-value pairs when initializing the hash, and this method of using literal initialization will eventually pass cmd/compile/internal/gc.maplit Initialization, let’s analyze the process of initializing the hash in this function:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
if len(entries) > 25 {
...
return
}
// Build list of var[c] = expr.
// Use temporaries so that mapassign1 can have addressable key, elem.
...
}
When the number of elements in the hash table is less than or equal to 25, the compiler will convert the literal initialized structure into the following code, adding all key-value pairs to the hash table at once:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
This initialization method is almost identical to arrays and slices, so it seems that the initialization of collection types has the same processing logic in the Go language.
Once the number of elements in the hash table exceeds 25, the compiler creates two arrays to store the keys and values respectively, and these key-value pairs are added to the hash through the for loop shown below:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
The two slices vstatk and vstatv are expanded here The editor will continue to expand it. For the specific expansion method, you can read the previous section to learn about slice initialization. However, no matter which method is used, the process of using literal initialization will use the keyword make in the Go language to create a new hash and append elements to the hash through the most primitive [] syntax.
Runtime
When the created hash is allocated to the stack and its capacity is less than BUCKETSIZE = 8, the Go language will use the following method to quickly initialize the hash during the compilation phase, which is also the compiler’s optimization for small-capacity hashes:
var h *hmap
var hv hmap
var bv bmap
h := &hv
b := &bv
h.buckets = b
h.hash0 = fashtrand0()
- Read and write operations
As a data structure, we must analyze its common operations, first of all, the principles of read and write operations. Hash tables are generally accessed through subscripts or traversals:
_ = hash[key]
for k, v := range hash {
// k, v
}
Although both methods can read hash table data, the functions used and the underlying principles are completely different. The former requires knowing the hash key and can only get the value corresponding to a single key at a time, while the latter can traverse all key-value pairs in the hash and does not need to know the hash key in advance when accessing data. Here we will introduce the former access method, and the second access method will be analyzed in detail in the range section.
Writing data structures generally refers to adding, deleting, and modifying. Adding and modifying fields use indexes and assignment statements, while deleting data in a dictionary requires the keyword delete:
hash[key] = value
hash[key] = newValue
delete(hash, key)
Access:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
The number of parameters accepted on the left side of the assignment statement determines the runtime method used:
- When accepting one parameter,
runtime.mapaccess1is used, which only returns a pointer to the target value; - When accepting two parameters, it is used
runtime.mapaccess2, in addition to returning the target value, it also returns aboolvalue used to indicate whether the value corresponding to the current key exists:
string
list list
- Initialization
- Initialize list through the
New() functionof the container/list package
variable name := list.New()
- Initialize list through the
var keyworddeclaration
var variable name list.List
- Common operations
package main
import "container/list"
func main() {
l := list.New()
// Add to the end
l.PushBack("canon")
// Add to the head
l.PushFront(67)
// Save the element handle after adding to the end
element := l.PushBack("fist")
// Add high after fist
l.InsertAfter("high", element)
// Add noon before fist
l.InsertBefore("noon", element)
// Use
l.Remove(element)
}
|  |
First element: l.Front()
Last element: l.Back()
Value of node e: e.Value e.Value.(int)
Merge two linked lists
l2.PushBackList(l2)
- Traversing the list
Traversing the double linked list requires the Front() function to obtain the head element. As long as the element is not empty, you can continue. Each traversal will call the element’s Next() function, the code is as follows.
l := list.New()
// Add to the end
l.PushBack("canon")
// Add to the head
l.PushFront(67)
for i := l.Front(); i != nil; i = i.Next() {
fmt.Println(i.Value)
}
The code output is as follows:
67
canon
heap
- iota
In a constant declaration, the predeclared identifier iota represents consecutive untyped integer constants. Its value is the index of the respective ConstSpec in the constant declaration, starting at 0. It can be used to construct a group of related constants.
type
- Boolean type: bool
*Number type:
uint8 the set of all unsigned 8-bit integers (0 to 255)
uint16 the set of all unsigned 16-bit integers (0 to 65535)
uint32 the set of all unsigned 32-bit integers (0 to 4294967295)
uint64 the set of all unsigned 64-bit integers (0 to 18446744073709551615)
int8 the set of all signed 8-bit integers (-128 to 127)
int16 the set of all signed 16-bit integers (-32768 to 32767)
int32 the set of all signed 32-bit integers (-2147483648 to 2147483647)
int64 the set of all signed 64-bit integers (-9223372036854775808 to 9223372036854775807)
float32 the set of all IEEE-754 32-bit floating-point numbers
float64 the set of all IEEE-754 64-bit floating-point numbers
complex64 the set of all complex numbers with float32 real and imaginary parts
complex128 the set of all complex numbers with float64 real and imaginary parts
byte alias for uint8
rune alias for int32
//This set of pre-declared numerical types, the size of which is related to the implementation
uint either 32 or 64 bits
int same size as uint
uintptr an unsigned integer large enough to store the uninterpreted bits of a pointer value
-
String type: string
-
Array type: define
var a [10]int, the array cannot be resized
a := [2]string{"a", "b"}
a := []string{"a", "b"}
a := [...]string{"a", "b"}
- Slice type: slice
[]T is a slice with element type T.
p := []int{2, 3, 5, 7, 11, 13}
The expression s[lo:hi] represents the slice elements from lo to hi-1, inclusive. Therefore s[lo:lo] is empty, while s[lo:lo+1] has one element.
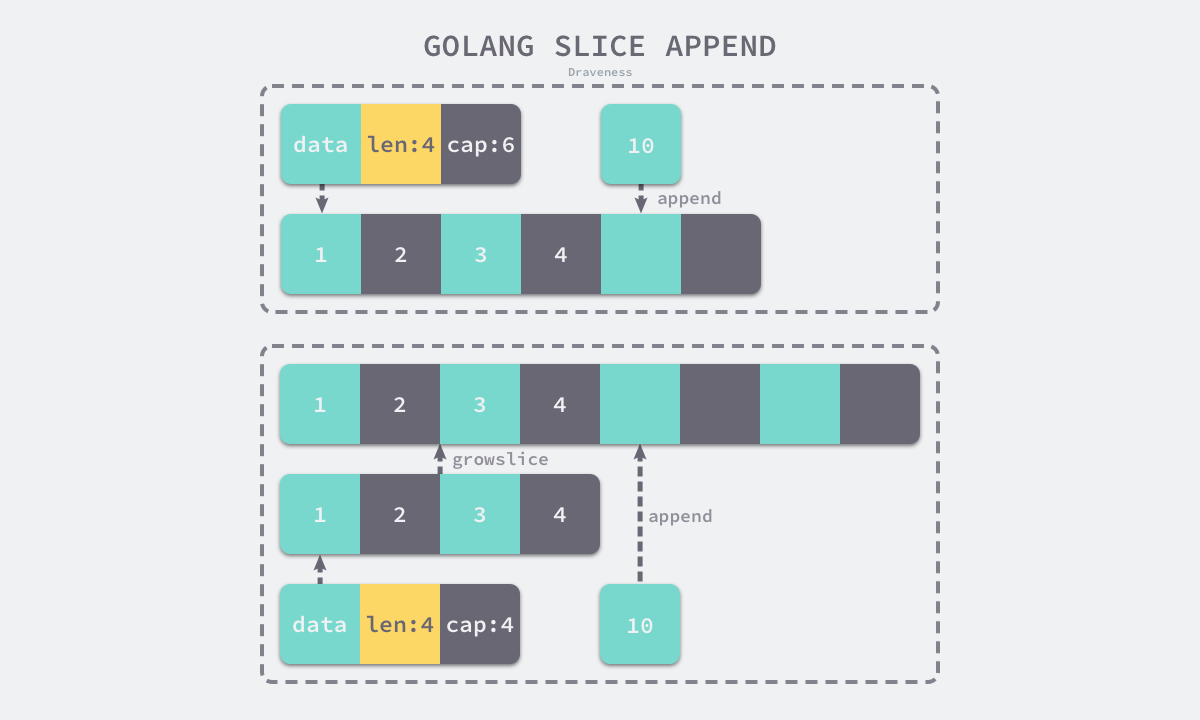
Note: The length of a slice can be explicitly specified by parameters during construction, or calculated by upper and lower subscripts during slicing. The capacity needs to take into account the starting position of the left subscript.
func main() {
a := make([]int, 5) // Specified length is 5, capacity is not set, then the same as length: len=5 cap=5
printSlice("a", a)
b := make([]int, 0, 5) // Specified length is 0, capacity is 5: len=0 cap=5
printSlice("b", b)
c := b[:2] // When slicing, the length is the difference between the lower and upper tables. When calculating the capacity, the left subscript starting position needs to be considered. Here, the left subscript starts from 0: len=2 cap=5
printSlice("c", c)
d := c[2:5] // When slicing, the length is the difference between the lower and upper tables. When calculating the capacity, the left subscript starting position needs to be considered. Here, the left subscript starts from 2: len=3 cap=5
printSlice("d", d)
}
func printSlice(s string, x []int) {
fmt.Printf("%s len=%d cap=%d %v\n",
s, len(x), cap(x), x)
}
The zero value of slice is nil. The length and capacity of a nil slice are 0.
Go provides a built-in function append to add elements to a slice:
func append(s []T, vs ...T) []T
- struct type
A structure is a collection of fields. The syntax of structure definition:
type Vertex struct {
X int
Y int
}
-
Pointer type
-
Function type
-
Interface type
An interface type specifies a method set called interface/interface. A variable of interface type can store values of any type whose method set is any superset of the interface. Such a type is said to implement the interface. The value of an uninitialized interface type variable is nil.
Interface types can specify methods explicitly through method specifications, or embed methods of other interfaces through interface type names.
// A simple File interface.
interface {
Read([]byte) (int, error)
Write([]byte) (int, error)
Close() error
}
- Map type
Maps must be created with make rather than new before use; a map with a value of nil is empty and cannot be assigned.
m := make(map[string]string) // The syntax is "map[key type]value type"
m["key1"] = "value1"
fmt.Println(m["key1"])
Or create directly by specifying key and value:
var m = map[string]string{
"key1": "value1",
"key2": "value2",
"key3": "value3", // Note that the last line must also end with a comma
}
The type of value can be ignored, such as the following:
var m = map[string]Vertex{
"Bell Labs": Vertex{
40.68433, -74.39967,
},
"Google": Vertex{
37.42202, -122.08408,
},
}
It can be simplified to:
var m = map[string]Vertex{
"Bell Labs": {40.68433, -74.39967},
"Google": {37.42202, -122.08408},
}
Modify map:
func main() {
m := make(map[string]int)
m["Answer"] = 42 //Insert or modify in map
fmt.Println("The value:", m["Answer"]) //Get value by key
m["Answer"] = 48 //Insert or modify in map
fmt.Println("The value:", m["Answer"])
delete(m, "Answer") //Delete key from map
fmt.Println("The value:", m["Answer"])
v, ok := m["Answer"] // Double assignment checks for the presence of a key, returning true if the second argument exists
fmt.Println("The value:", v, "Present?", ok)
}
The initial capacity does not constrain its size: maps can grow to accommodate the number of items stored in them, except for nil maps, which are equivalent to empty maps, but cannot have any elements added.
- channel types
Channels provide a mechanism for concurrently executing functions to communicate by sending and receiving values of a specified element type. The value of an uninitialized channel is nil.
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
The optional <- operator specifies the channel direction, either send or receive. If no direction is given, the channel is bidirectional. Channels can be restricted to send or receive only by assignment or explicit conversion.
chan T // can be used to send and receive values of type T
chan<- float64 // can only be used to send float64s
<-chan int // can only be used to receive ints
Statements
- Send Statements
https://golang.org/ref/spec#Send_statements
A send statement sends a value on a channel. The channel expression must be of the channel type, the channel direction must allow send operations, and the type of the value to be sent must be assignable to the channel’s element type.
SendStmt = Channel "<-" Expression .
Channel = Expression .
Both the channel and the value expression are evaluated before communication begins. Communication blocks until the send can proceed. Sends on unbuffered channels proceed if the receiver is ready. Sends on buffered channels proceed if there is room in the buffer. Sends on closed channels cause a runtime panic. Sends on nil channels block forever.
ch <- 3 // send value 3 to channel ch
- Control flow statements
if statement
if v := math.Pow(x, n); v < lim {
// v is accessible here
return v
}
// v is not accessible here
switch statement
The syntax of switch is similar to for and if, with the same rules for using brackets and curly braces, the same permission to execute a simple statement before switch, and the same variable access range restrictions:
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
fmt.Printf("%s.", os)
}
After hitting a case substatement and executing it, the switch statement in golang will automatically terminate the branch and end the switch statement. This is the default behavior, which is different from C and Java, which will automatically continue to the next branch matching and require a clear break to exit.
If you want to continue executing the following case substatements, you need to use the fallthrough statement at the end of the case substatement.
for statement
Go has only one loop structure, the for loop.
sum := 0
for
i := 0; i < 10; i++ {
sum += i
}
It can also be similar to while loops in C and Java:
sum := 1
for sum < 1000 {
sum += sum
}
for-range statement
The “for” statement with the “range” clause iterates over all entries of an array, slice, string, or map, or values received on a channel. For each entry, it assigns the iteration value to the corresponding iteration variable if it exists, and then executes the block.
If you are looping over an array, slice, string, or map, or reading from a channel, the range clause can manage the loop.
for key, value := range oldMap {
newMap[key] = value
}
If you only need the first item (key or index) in the range, discard the second item.
for key := range m {
if key.expired() {
delete(m, key)
}
}
If you only need the second item (value) in the range, use a blank identifier (underscore) to discard the first item.
sum := 0
for _, value := range array {
sum += value
}
go statement
The “go” statement starts executing a function call in the same address space as a separate concurrent control thread or goroutine.
select statement
select is a control statement in Golang, with a syntax similar to the switch statement. However, select is only used for communication, and each case must be an IO operation.
A select without a default statement will block until a case is satisfied:
ch1 := make (chan int, 1)
ch2 := make (chan int, 1)
select {
case <-ch1:
fmt.Println("ch1 pop one element")
case <-ch2:
fmt.Println("ch2 pop one element")
}
If both cases are satisfied at the same time, a case statement will be executed randomly, and other case statements will not be executed.
If you don’t want to block, you can bring a default substatement:
select {
case <-ch1:
fmt.Println("ch1 pop one element")
case <-ch2:
fmt.Println("ch2 pop one element")
default:
fmt.Println("not ready yet")
}
If both case conditions are not satisfied, jump directly to the default process without blocking.
break Statement
The “break” statement terminates execution of the innermost “for”, “switch”, or “select” statement in the same function.
BreakStmt = "break" [ Label ] .
Labels must surround the “for”, “switch”, or “select” statements, if any, and the label is the execution termination.
goto Statement
The “goto” statement transfers control to the corresponding labeled statement in the same function.
GotoStmt = "goto" Label .
goto Error
Execution of a “goto” statement must not cause any variables after the goto to enter a scope that it has not already been in. For example, this example:
goto L // BAD
v := 3
L:
is an error because the jump to label L skips the creation of v.
A “goto” statement outside a block cannot jump to a label within that block. For example, this example:
if n%2 == 1 {
goto L1
}
for n > 0 {
f()
n--
L1:
f()
n--
}
is incorrect because label L1 is inside the block of the “for” statement, but goto is not.
fallthrough statement
The “fallthrough” statement transfers control to the first statement of the next case clause in a “switch” statement. It can only be used as the last non-empty statement in such a clause.
defer statement
The defer statement delays the execution of a function until the outer function returns, and is usually used to perform cleanup operations.
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close()
dst, err := os.Create(dstName)
if err != nil {
return
}
defer dst.Close()
return io.Copy(dst, src)
}
Other usage scenarios, such as releasing mutex:
mu.Lock()
defer mu.Unlock()
Language Features
Functions
- Multiple Return Values
One unusual feature of Go is that functions and methods can return multiple values. This form can be used to improve several awkward idioms in C programs: built-in error returns, such as -1 for EOF and modifying parameters passed by address.
- init functions
In addition to initialization that cannot be expressed in declarations, a common use of init functions is to verify or repair the correctness of the program state before actual execution begins.
func init() {
if user == "" {
log.Fatal("$USER not set")
}
if home == "" {
home = "/home/" + user
}
if gopath == "" {
gopath = home + "/go"
}
// gopath may be overridden by --gopath flag on command line.
flag.StringVar(&gopath, "gopath", gopath, "override default GOPATH")
}
- Function call
Parameter passing:
Value passing: The parameters are copied when the function is called, and the callee and the caller hold two unrelated data;
Reference passing: The pointer of the parameter is passed when the function is called, and the callee and the caller hold the same data. Any modification made by either party will affect the other party.
The Go language chooses the value passing method. Whether it is passing basic types, structures or pointers, the passed parameters will be copied.
If you want the variable in the function to modify the variable outside the function, you can pass in the address of the variable &, and the variable will be operated in the function as a pointer. The effect is similar to reference.
- Method
Function: does not belong to any structure, type, and has no receiver
go func Add(a, b int) int { return a + b }
Method: a specific structure, type association, with a receiver
type person struct {
name string
}
func (p person) String() string{
return "the person name is "+p.name
}
A function accepts some parameters as input and produces some output. For the same input, the function always produces the same output. This means that it does not depend on state. The type is passed as a parameter to the function.
A method in Go is a function with a specific receiver(type) parameter. It defines the behavior of the type and it should use the state of the type.
There are two types of receivers in Go: value receivers and pointer receivers.
– Using value receivers: When calling, the method actually uses a copy of the value receiver, so any operation on the value will not affect the original value receiver (or type variable).
– Using pointer receivers: Because the pointer receiver passes a copy of the pointer to the original value (i.e., a copy of the pointer), which still points to the value of the original type, when it is modified, it will also affect the value of the original value receiver (type variable).
Summary:
When calling a method, the receivers passed are essentially copies, but they can be copies of values or copies of pointers to this value. Pointers have the characteristic of pointing to the original value, so if the value pointed to by the pointer is modified, the original value is also modified.
- Closure
Closure = function + application environment
Objects are data with behaviors, and closures are behaviors with data.
Interface
An interface type is a set of methods defined by a set of methods.
// Define an interface and its methods
type Abser interface {
Abs() float64
}
type Vertex struct {
X, Y float64
}
// Let the structure implement the methods required by the interface
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
Values of interface type can hold any value that implements these methods.
var a Abser
v := Vertex{3, 4}
a = &v // *Vertex implements Abser
Concurrency
- Don’t communicate via shared memory
In mainstream programming languages, when you think of concurrent execution of code, you mostly think of a bunch of threads running in parallel, performing some complex operation. Well, in most cases, you need to share data structures/variables/memory/whatever between different threads. You can do this by locking this piece of memory so that no two threads can access/write to it at the same time, or you just let it roam free and hope for the best. In a lot of popular programming languages, this is usually how different threads “communicate”, which usually leads to all kinds of problems like race conditions, memory management, random-weird-unexplained exceptions-waking-you-up-all-night… etc.
- Share memory by communicating instead
So how does Go do it? Instead of locking variables to share memory, Go allows values stored in variables to be communicated (or sent) from one thread to another (actually, it’s not exactly a thread, but we’ll treat it as one for now). The default behavior is that both the thread sending the data and the thread receiving the data will wait until the value reaches its destination. The “waiting” of the threads forces proper synchronization between the threads when exchanging data. Think about concurrency this way before rolling up your sleeves and starting to design your code; it makes your software more stable.
To be more specific: stability comes from the fact that by default, neither the sending thread nor the receiving thread will do anything until the value transfer is complete. Meaning that there will be no race conditions or similar issues with either thread operating on the data before the other thread has finished transferring it.
Go provides native features that you can use to implement this behavior without calling additional libraries or frameworks, the behavior is simply built into the language. Go also allows you to have a “buffered channel” if you need it. This means that in some cases, you don’t want both threads to lock or synchronize until a value is transferred, instead, you want the synchronization/locking to happen only when you fill up the channel between the two threads with a predefined number of pending values.
However, it should be warned that this pattern can be overused. You have to feel when to use it, or when to revert to the old-fashioned shared memory model. For example, reference counting is best protected inside a lock, and the same is true for file access. Go will support you there too with the synchronization package.
- Concurrent coding in golang
In Go, a “goroutine” serves the concept of thread we described above. In fact, it is not really a thread, it is basically a function that can run concurrently with other goroutines in the same address space. They are multiplexed between O.S. threads, so if one thread blocks, the others can continue to run. All synchronization and memory management is done natively by Go. The reason they are not true threads is that they are not necessarily parallel all the time. However, due to the multiplexing and synchronization, you get concurrent behavior. To start a new goroutine, you just use the keyword “go”.
go processdataFunction()
The “go channel” is another key concept for implementing concurrency in Go. This is the channel used for memory communication between goroutines. To create a channel, you use “make”.
myChannel := make(chan int64)
Creating a buffered channel to allow more values to be queued before goroutines wait would look like this:
myBufferedChannel := make(chan int64,4)
In both examples above, I have assumed that the channel variable has not been created before. That’s why I use “:=” to create variables with inferred types instead of “=”, because “=” only assigns values and will cause a compilation error if the variable has not been declared before.
Now to use a channel, you can use the “<-” symbol. The value sent by the goroutine will be assigned to the channel like this.
mychannel <- 54
The goroutine that receives the value will extract the value from the channel and assign it to a new variable, like this:
myVar := <- mychannel