
Content
Table of Contents
- 1. Understand the basics of Web and network
- 2. Simple HTTP protocol
- 2.1 HTTP protocol is used for communication between clients and servers
- 2.2 Communication is achieved through the exchange of requests and responses
- 2.3 HTTP is a protocol that does not save state
- 2.4 Request URI to locate resources
- 2.5 HTTP methods that inform the server of its intentions
- 2.7 Persistent connection saves communication traffic
- 2.8 Using Cookie State Management
- 3. HTTP information in HTTP message
- 4. HTTP status code of the returned result
- 4.4.1 400 Bad Request
- 5. Web servers that collaborate with HTTP
- 6. HTTP header
- 7. HTTPS for Web security
- 8. Authentication to confirm the identity of the accessing user
- 9. HTTP-based function addition protocol
- 10. Technology for building web content
- 11. Web attack techniques
1. Understand the basics of Web and network
1.3 Network basics TCP/IP
Layered management of TCP/IP:
The advantage is that if a certain place needs to change the design, all parts must be replaced as a whole, but after layering, only the changed layer needs to be replaced. After planning the interface between the layers, the design within each layer can be changed freely.
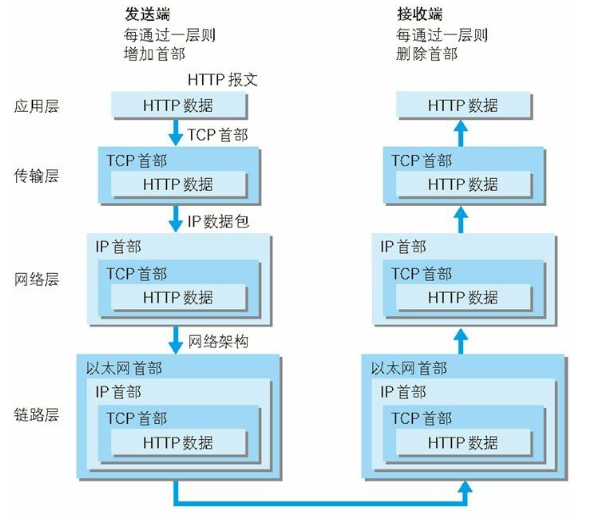
1.4 Protocols closely related to HTTP: IP, TCP and DNS
1.4.1 IP protocol responsible for transmission
The IP Internet Protocol is located in the network layer, and its function is to transmit various data packets to each other. The two important conditions involved are IP address and MAC address.
IP address: indicates the address assigned to the node;
MAC address: the fixed address of the network card;
IP address—>MAC address: ARP protocol is a protocol used to resolve addresses
1.4.2 TCP protocol to ensure reliability
TCP is located in the transport layer and provides reliable byte stream services. Byte stream services refer to the management of large blocks of data into packets in the form of segments.
The TCP protocol uses a three-way handshake:

- Why must a three-way handshake be used? What problems will arise if a two-way handshake is used?
1.5 DNS service responsible for domain name resolution
DNS (Domain Name System) is located at the application layer and provides resolution services from domain names to IP addresses.
The DNS protocol provides querying IP addresses from domain names, or querying domain names from IP addresses
1.6 The relationship between various protocols and HTTP protocol

2. Simple HTTP protocol
2.1 HTTP protocol is used for communication between clients and servers
Client: the end that requests access to resources such as text or images;
Server: the end that provides resource responses;
Sometimes, according to the actual situation, two computers may call each other as clients and servers, but the HTTP protocol can clearly distinguish which end is the client and which end is the server.
2.2 Communication is achieved through the exchange of requests and responses
- Requests must be sent by the client, and the server will not send a response before receiving the request
-
Request message
-
Response message
2.3 HTTP is a protocol that does not save state
When using the HTTP protocol, each time a new request is sent, a corresponding new response will be generated. The protocol itself does not retain all previous request or response message information.
2.4 Request URI to locate resources
The HTTP protocol uses URI to locate resources on the Internet
2.5 HTTP methods that inform the server of its intentions
- GET: Get resources
The GET method is used to request access to resources identified by URIs. The specified resource is parsed by the server and then returns the response content.
- POST: Transfer entity body
Although the GET method can also transfer the body of the entity, the POST method is generally used to transfer the entity
- put: Transfer files
The PUT method transfers files just like the file upload of the FTP protocol. It requires that the file content be included in the body of the request message and then saved to the location specified by the request URI. However, this method itself does not have a verification mechanism, and anyone can upload files, which poses a security problem
- HEAD: Get the message header
The HEAD method is the same as the GET method, except that it does not return the message body.
- DELETE: Delete files
The DELETE method is used to delete files, which is the opposite of PUT. It does not have a verification mechanism, so general websites do not use the DELETE method.
- OPTIONS: Inquiry for supported methods
Methods used to query supported resources specified by the request URI
- TRACE: Tracking path
A method that allows the web server to loop back the previous request communication to the client, used to query how the sent request is processed and modified
- CONNECT: Requires the use of a tunnel protocol to connect to the proxy
Requires the establishment of a tunnel when communicating with the proxy server, and implements TCP communication using the tunnel protocol. The SSL and TLS protocols are mainly used to encrypt the communication content and transmit it through the network tunnel.

2.7 Persistent connection saves communication traffic
In the initial version of the HTTP protocol, a TCP connection must be disconnected for each HTTP communication. However, as the number of documents containing a large number of images increases, each request will cause unnecessary TCP connection establishment and disconnection
2.7.1 Persistent connection
Features: As long as either end does not explicitly request a disconnection, the TCP connection state is maintained.
In HTTP/1.1, all connections are persistent connections by default, but this is not standardized in HTTP/1.0
2.7.2 Pipelining
Persistent connections make it possible to send most requests in a pipelined manner. In the past, after sending a request, you had to wait and receive a response before sending the next request. After the emergence of pipeline technology, you can send the next request directly without waiting for a response.
2.8 Using Cookie State Management
Cookies will notify the client to save cookies based on a header field called Set-Cookie in the response message sent from the server. The next time the client sends a request to the server, the client will automatically add the cookie value to the request message and send it out.
3. HTTP information in HTTP message
3.1 HTTP message
HTTP message can be roughly divided into message header and message body
3.2 Structure of request message and response message
Request message:
Message header:
Request line;
Request header field;
Common header field;
Others;
Blank line (CR+LF)
Message body:
3.3 Encoding improves transmission rate
3.3.1 Difference between message body and entity body
The body of HTTP message is used to transmit the entity body of request or response.
Usually, the message body is equal to the entity body. Only when the encoding operation is performed during transmission, the content of the entity body changes, which leads to the difference between it and the message body.
3.3.2 Content encoding for compressed transmission
Common content encodings include the following
-
gzip (GNU zip)
-
compress (standard compression for UNIX systems)
-
deflate (zlib)
-
identity (no encoding)
3.3.3 Blocked transmission encoding for segmented transmission
When transmitting large amounts of data, the data can be segmented into multiple blocks so that the browser can display the page gradually
3.4 Sending a collection of multi-part objects of various data
The body of a message sent may contain multiple types of entities, which is usually used when uploading images or text files.
3.5 Range request for obtaining partial content
In the past, users could not access the Internet with the high-speed bandwidth that is available today. At that time, downloading a slightly larger image or file was already very difficult. If the network was interrupted during the download process, it would have to start over. In order to solve the above problem, a recoverable mechanism is needed. Recovery means that the download can be resumed from the previous interruption point.
To implement this function, the entity range to be downloaded needs to be specified. Like this, a request that specifies a range is called a range request.
For a resource of 10,000 bytes, if a range request is used, only the resource within 5001 to 10,000 bytes can be requested.
When performing a range request, the header field Range is used to specify the byte range of the resource.
Range: bytes = 5001 - 10000
Range: bytes = 5001 -
Range: bytes = - 3000, 5001 - 10000 (multiple ranges)
For a range request, the response will return a response message with a status code of 206 Partial Content. If the server cannot respond to a range request, it will return a status code of 200 OK and the complete entity content.
3.6 Content negotiation returns the most appropriate content
The same web site may have multiple pages with the same content. For example, the English and Chinese versions of web pages have the same content, but use different languages. When the default language of the browser is English or Chinese, when accessing a web page with the same URI, the corresponding English or Chinese version of the web page will be displayed. This mechanism is called content negotiation.
The content negotiation mechanism refers to the negotiation between the client and the server on the content of the response resource, and then providing the most suitable resource to the client. Content negotiation uses the language, character set, encoding method, etc. of the response resource as the basis for judgment.
4. HTTP status code of the returned result
4.1 Status code informs the request result returned from the server
Status code category:
Only 14 types are commonly used.
4.2 2XX success
4.2.1 200 OK
Indicates that the request sent from the client was processed normally on the server.
In the response message, the information returned with the status code will change depending on the method. For example, when the GET method is used, the entity of the corresponding requested resource will be returned as a response; when the HEAD method is used, the entity header of the corresponding requested resource will not be returned with the message body as a response (that is, only the header is returned in the response, and the entity body will not be returned).
4.2.2 204 NO Content
Indicates that the request received by the server has been successfully processed, but the returned response message does not contain the entity body.
In addition, it is not allowed to return any entity body. For example, when a request is processed from a browser and a 204 response is returned, the page displayed by the browser will not be updated.
4.2.3 206 PartialContent
Indicates that the client made a range request, and the server successfully executed this part of the GET request. The response message contains the entity content specified by Content-Range.
4.3 3XX Redirection
4.3.1 301 Moved Permanently
Permanent redirection.
This status code indicates that the requested resource has been assigned a new URI, and the URI that the resource now refers to should be used in the future. In other words, if the URI corresponding to the resource has been saved as a bookmark, it should be saved again according to the URI indicated in the Location header field.
4.3.2 302 Found
Temporary redirection.
This status code indicates that the requested resource has been assigned a new URI, and the user is expected to use the new URI (this time) to access it. Similar to the 301 Moved Permanently status code, the resource represented by the 302 status code is not permanently moved, but only temporarily. In other words, the URI corresponding to the moved resource may change in the future. For example, the user saves the URI as a bookmark, but does not update the bookmark like when the 301 status code appears, but still retains the URI corresponding to the page that returns the 302 status code.
4.3.3 303 See Other
Since the resource corresponding to the request has another URI, the GET method should be used to obtain the requested resource.
The 303 status code has the same function as the 302 Found status code, but the 303 status code clearly indicates that the client should use the GET method to obtain the resource, which is different from the 302 status code. For example, when the POST method is used to access the CGI program, and the result of its execution is to hope that the client can redirect to another URI with the GET method, the 303 status code is returned. Although the 302 Found status code can also achieve the same function, it is most ideal to use the 303 status code here.
4.3.4 304 Not Modified
Indicates that when the client sends a conditional request, the server allows the request to access the resource, but the condition is not met.
When the 304 status code is returned, it does not contain any body part of the response. Although 304 is classified in the 3XX category, it has nothing to do with redirection.
4.3.5 307 Temporary Redirect
Temporary redirection.
This status code has the same meaning as 302 Found. Although the 302 standard prohibits POST from being transformed into GET, it is not followed in actual use.
4.4 4XX Client Error
##
4.4.1 400 Bad Request
Indicates that there is a syntax error in the request message.
When an error occurs, the request content needs to be modified and sent again. In addition, the browser will treat this status code like 200 OK.
4.4.2 401 Unauthorized
Indicates that the request sent needs to have authentication information that passes HTTP authentication (BASIC authentication, DIGEST authentication).
In addition, if a request has been made before, it means that user authentication failed.
The response returned with 401 must contain a WWW-Authenticate header applicable to the requested resource to challenge the user information. When the browser receives a 401 response for the first time, a dialog window for authentication will pop up.
4.4.3 403 Forbidden
Indicates that access to the requested resource is denied by the server.
The server does not need to give a detailed reason for the rejection, but if you want to explain it, you can describe the reason in the body of the entity so that users can see it.
Failure to obtain access authorization to the file system, some problems with access permissions (attempting to access from an unauthorized source IP address), etc. may be the reasons for the occurrence of 403.
4.4.4 404 Not Found
Indicates that the requested resource cannot be found on the server.
In addition, it can also be used when the server rejects the request and does not want to explain the reason.
4.5 5XX Server Error
4.5.1 500 Internal Server Error
Indicates that an error occurred on the server when executing the request. It may also be a bug in the web application or some temporary failure.
4.5.2 503 Service Unavailable
Indicates that the server is temporarily overloaded or is undergoing maintenance and cannot process the request now.
5. Web servers that collaborate with HTTP
5.1 Implementing multiple domain names with a single virtual host
The HTTP/1.1 specification allows one HTTP server to build multiple Web sites. For example, a provider of Web hosting services can use one server to serve multiple customers, or run different websites with the domain name held by each customer. This is because the function of the virtual host (also known as a virtual server) is utilized.
If a server hosts two domain names, www.tricorder.jp and www.hackr.jp, they use the same IP address. After using the DNS service to resolve the domain name, the access IP addresses of the two are the same.
Under the same IP address, since a virtual host can host multiple Web sites with different host names and domain names, when sending an HTTP request, the URI of the host name or domain name must be fully specified in the Host header.
5.2 Communication data forwarding program: proxy, gateway, tunnel
In HTTP communication, in addition to the client and server, there are also some applications for communication data forwarding, such as proxy, gateway, tunnel.
5.2.1 Proxy
A proxy is an application with forwarding function. It plays the role of “middleman” between the server and the client, receiving requests sent by the client and forwarding them to the server, and also receiving responses returned by the server and forwarding them to the client.
The basic behavior of the proxy server is to receive requests sent by the client and forward them to other servers. The proxy does not change the request URI and will directly send it to the target server holding the resource in front.
Every time a request or response is forwarded through the proxy server, the Via header information will be appended.
- Reasons for using a proxy server are:
-
Use caching technology (explained later) to reduce network bandwidth traffic;
-
Access control for specific websites within the organization;
-
The main purpose is to obtain access logs, etc.
- Two ways to use a proxy:
- Whether to use cache;
Caching proxy: When the proxy forwards a response, the caching proxy will save a copy of the resource (cache) on the proxy server in advance. When the proxy receives a request for the same resource again, it can return the previously cached resource as a response instead of obtaining the resource from the source server.
- Whether to modify the message;
Transparent proxy: When forwarding a request or response, the proxy type that does not process the message is called a transparent proxy. Conversely, a proxy that processes the message content is called a non-transparent proxy.
5.2.2 Gateway
A gateway is a server that forwards communication data from other servers. When receiving a request from a client, it processes the request as if it were a source server that owns the resource. Sometimes the client may not even notice that its communication target is a gateway.
- Function:
-
Gateway can be used to convert HTTP request into other protocol communication;
-
Gateway can improve the security of communication, because the communication line between the client and the gateway can be encrypted to ensure the security of the connection. For example, the gateway can connect to the database and use SQL statements to query data. In addition, when making credit card settlement on a Web shopping website, the gateway can be linked with the credit card settlement system.
5.2.3 Tunnel
Tunnel is an application that transfers between the client and the server, which are far apart, and maintains the communication connection between the two parties.
Tunnel can establish a communication line with other servers as required, and then use encryption methods such as SSL to communicate.
- Function: Ensure that the client can communicate securely with the server.
The tunnel itself will not parse the HTTP request. In other words, the request is forwarded to the subsequent server as it is. The tunnel will end when the two communicating parties disconnect.
5.3 Cache for saving resources
Cache refers to the copy of resources saved in the proxy server or the client’s local disk. Using cache can reduce the number of visits to the source server, thus saving communication traffic and communication time.
5.3.1 Validity period of cache
Even if there is a cache, the validity of the resource will be confirmed with the source server due to factors such as the client’s request and the validity period of the cache. If the cache is judged to be invalid, the cache server will obtain the “new” resource from the source server again.
5.3.2 Client cache
If the browser cache is valid, there is no need to request the same resource from the server again, and it can be read directly from the local disk.
In addition, the same point as the cache server is that when the cache is judged to be expired, the validity of the resource will be confirmed with the source server. If the browser cache is judged to be invalid, the browser will request new resources again.
6. HTTP header
6.1 HTTP message header
The HTTP header must be included in the request and response messages of the HTTP protocol. The header content provides the required information for the client and server to process the request and response respectively.
6.2 HTTP header fields
6.3 HTTP/1.1 common header fields
6.4 Request header fields
6.5 Response header fields
6.6 Entity header fields
6.7 Header fields for cookies
7. HTTPS for Web security
7.1 Disadvantages of HTTP
- Disadvantages:
-
Communication uses plain text (not encrypted), and the content may be eavesdropped;
-
The identity of the communicating party is not verified, so it may be disguised;
-
The integrity of the message cannot be proved, so it may have been tampered with;
7.1.1 Communication using plain text may be eavesdropped
HTTP messages are sent in plain text.
- TCP/IP is a network that may be eavesdropped
It is not difficult to eavesdrop on communications on the same segment. You only need to collect data packets (frames) flowing on the Internet. The analysis of the collected data packets can be handed over to those packet capture or sniffer tools.
- Encryption processing to prevent eavesdropping
Encryption objects:
1. Communication encryption
There is no encryption mechanism in the HTTP protocol, but it can be used in combination with SSL (Secure Socket Layer) or TLS (Transport Layer Security) to encrypt the HTTP communication content. After establishing a secure communication line with SSL, HTTP communication can be carried out on this line. HTTP used in combination with SSL is called HTTPS (HTTP Secure) or HTTP over SSL.
2. Content encryption
In this case, the client needs to encrypt the HTTP message before sending the request.
In order to achieve effective content encryption, the premise is that the client and the server are required to have encryption and decryption mechanisms at the same time. Mainly used in Web services.
7.1.2 Failure to verify the identity of the communication party may lead to impersonation
The request and response in the HTTP protocol will not confirm the communication party. In other words, there are similar questions such as “whether the server is the host actually specified by the URI in the request, and whether the returned response is really returned to the client that actually made the request”.
- Anyone can initiate a request
In HTTP protocol communication, since there is no processing step to confirm the communication party, anyone can initiate a request. In addition, as long as the server receives the request, it will return a response regardless of who the other party is (but only under the premise that the IP address and port number of the sender are not restricted by the Web server).
- Failure to confirm the communication party will lead to the following risks
-
It is impossible to determine whether the Web server to which the request is sent is the server that returns the response according to the real intention. It may be a disguised Web server.
-
It is impossible to determine whether the client to which the response is returned is the client that receives the response according to the real intention. It may be a disguised client.
-
It is impossible to determine whether the communicating party has access rights. Because some Web servers store important information, they only want to give communication rights to specific users.
-
It is impossible to determine where the request comes from and who made it.
-
Even meaningless requests will be accepted. It is impossible to prevent DoS attacks (Denial of Service, denial of service attacks) under massive requests.
- Find out the opponent’s certificate
Although the communication party cannot be determined using the HTTP protocol, it can be determined if SSL is used. SSL not only provides encryption processing, but also uses a method called certificate, which can be used to determine the party.
Certificates are issued by a trusted third-party organization to prove that the server and client actually exist. In addition, it is extremely difficult to forge a certificate from a technical point of view. Therefore, as long as the certificate held by the communication party (server or client) can be confirmed, the true intention of the communication party can be determined.
7.1.3 The integrity of the message cannot be proved, and it may have been tampered with
- The received content may be wrong
Since the HTTP protocol cannot prove the integrity of the communication message, there is no way to know if the content of the request or response has been tampered with during the period from the time the request or response is sent to the time the other party receives it. In other words, there is no way to confirm that the request/response sent and the request/response received are the same.
- How to prevent tampering
Although there are methods to determine the integrity of the message using the HTTP protocol, in fact, it is not convenient and reliable. Among them, the commonly used methods are hash value verification methods such as MD5 and SHA-1, and digital signature methods used to confirm files.
Unfortunately, these methods still cannot guarantee that the confirmation results are 100% correct. Because if PGP and MD5 themselves are rewritten, users will not be able to realize it. In order to effectively prevent these disadvantages, it is necessary to use HTTPS. SSL provides authentication, encryption processing and digest functions. It is very difficult to ensure integrity with HTTP alone, so this goal is achieved by combining it with other protocols.
7.2 HTTPS = HTTP + encryption + authentication + integrity protection
7.2.1 HTTP Adding encryption processing, authentication and integrity protection is HTTPS
7.2.2 HTTPS is HTTP with SSL shell
HTTPS is not a new protocol at the application layer, but the HTTP communication interface is replaced by SSL and TLS protocols.
Usually, HTTP communicates directly with TCP. When SSL is used, it evolves into communicating with SSL first, and then SSL and TCP communicate. After adopting SSL, HTTP has the encryption, certificate and integrity protection functions of HTTPS.
Other protocols such as SMTP and Telnet running at the application layer can be used with SSL.
7.2.3 Public key encryption technology for mutual key exchange
SSL adopts a public key encryption processing method.
- The dilemma of shared key encryption
The method of using the same key for encryption and decryption is called shared key encryption, also known as symmetric key encryption. However, when encrypting with a shared key, the key must also be sent to the other party. How can it be transferred safely?
- Public key encryption using two keys
Public key encryption solves the difficulties of shared key encryption very well. Public key encryption uses a pair of asymmetric keys, one is called a private key and the other is called a public key.
Using public key encryption, the party sending the ciphertext uses the other party’s public key for encryption. After the other party receives the encrypted information, it uses its own private key to decrypt it. In this way, there is no need to send a private key for decryption, nor is it necessary to send a private key for decryption.You must worry about the key being eavesdropped and stolen by attackers.
- HTTPS uses a hybrid encryption mechanism
HTTPS uses a hybrid encryption mechanism that uses both shared key encryption and public key encryption. If the key can be exchanged securely, then it is possible to consider using only public key encryption for communication. However, compared with shared key encryption, public key encryption is slower. Therefore, we should make full use of the advantages of both and combine multiple methods for communication. Use public key encryption in the key exchange link, and use shared key encryption in the subsequent communication exchange message establishment stage.
7.2.4 Certificate to prove the correctness of the public key
There are still some problems with the public key encryption method. That is, it is impossible to prove that the public key itself is the real public key. For example, when you are about to establish communication with a server under the public key encryption method, how to prove that the received public key is the public key issued by the server originally expected. Perhaps during the transmission of the public key, the real public key has been replaced by the attacker.
To solve the above problems, you can use public key certificates issued by digital certificate certification authorities (CA) and their related agencies.
7.2.5 HTTPS secure communication mechanism
SSL is slow in two ways. One is slow communication. The other is slow processing speed due to the large consumption of resources such as CPU and memory. Compared with HTTP, the network load may be 2 to 100 times slower. In addition to connecting with TCP and sending HTTP requests and responses, SSL communication must also be performed, so the overall processing volume will inevitably increase.
8. Authentication to confirm the identity of the accessing user
Some web pages are only intended to be viewed by specific people, or simply visible only to the person himself. To achieve this goal, the authentication function is essential.
8.1 What is authentication?
Check the information that only I know:
Password, dynamic token, digital certificate, biometric authentication, IC card
Authentication methods used by HTTP:
BASIC authentication (basic authentication), DIGEST authentication (digest authentication), SSL client authentication, FormBase authentication (form-based authentication)
8.2 BASIC authentication
It is the authentication method between the web server and the communication client.
Step 1: When the requested resource requires BASIC authentication, the server will return a response with the WWW-Authenticate header field along with the status code 401 Authorization Required. This field contains the authentication method (BASIC) and the Request-URI security domain string (realm).
Step 2: In order to pass the BASIC authentication, the client that receives the status code 401 needs to send the user ID and password to the server. The string content sent is composed of the user ID and password, which are connected by a colon (:) and then processed by Base64 encoding.
Assuming the user ID is guest and the password is guest, the string guest:guest will be formed when they are connected. Then, after Base64 encoding, the final result is Z3Vlc3Q6Z3Vlc3Q=. After writing this string into the header field Authorization, send the request.
When the user agent is a browser, the user only needs to enter the user ID and password, and then the browser will automatically complete the conversion to Base64 encoding.
Step 3: The server that receives the request containing the header field Authorization will verify the correctness of the authentication information. If the verification is successful, a response containing the Request-URI resource will be returned.
Although BASIC authentication uses Base64 encoding, it is not encrypted. It can be decoded without any additional information. In other words, since the plain text is decoded to the user ID and password, if it is eavesdropped during the BASIC authentication process on non-encrypted communication lines such as HTTP, the possibility of theft is very high.
8.3 DIGEST authentication
To make up for the weaknesses of BASIC authentication, DIGEST authentication has been available since HTTP/1.1. DIGEST authentication also uses the challenge/response method, but does not send plain text passwords directly like BASIC authentication.
Step 1: When requesting a resource that requires authentication, the server will return a response with the WWW-Authenticate header field along with the status code 401 Authorization Required. This field contains the temporary challenge code (random number, nonce) required for challenge-response authentication.
The header field WWW-Authenticate must contain information from the realm and nonce fields. The client relies on sending these two values back to the server for authentication.
A nonce is an arbitrary random string generated each time a 401 response is returned. This string is usually recommended to be composed of Base64-encoded hexadecimal numbers, but the actual content depends on the specific implementation of the server.
Step 2: The client that receives the 401 status code returns a response containing the header field Authorization information required for DIGEST authentication.
The header field Authorization must contain the field information of username, realm, nonce, uri, and response. Among them, realm and nonce are the fields in the response previously received from the server.
Username is the user name that can be authenticated within the realm limit.
uri (digest-uri) is the value of Request-URI, but considering that the value of Request-URI may be modified after being forwarded by the proxy, a copy will be made in advance and saved in uri.
Response can also be called Request-Digest, which stores the password string after MD5 operation to form a response code.
For other entities in the response, please refer to the request header field Authorization in Chapter 6. In addition, the calculation rules for Request-Digest are relatively complicated. Interested readers may wish to study RFC2617 in depth.
Step 3: The server that receives the request containing the Authorization header field will confirm the correctness of the authentication information. After the authentication is passed, a response containing the Request-URI resource is returned.
DIGEST authentication provides a higher security level than BASIC authentication, but it is still weaker than HTTPS client authentication. DIGEST authentication provides a protection mechanism to prevent password eavesdropping, but there is no protection mechanism to prevent user impersonation.
DIGEST authentication, like BASIC authentication, is not as convenient and flexible to use, and still does not meet the high security level pursued by most Web sites.
8.4 SSL Client Authentication
SSL client authentication is a way to complete authentication through HTTPS client certificates. With the authentication of client certificates (explained in the HTTPS chapter), the server can confirm whether the access comes from a logged-in client.
8.4.1 Steps of SSL Client Authentication
To achieve the purpose of SSL client authentication, the client certificate needs to be distributed to the client in advance, and the client must install this certificate.
Step 1: After receiving a request for authentication resources, the server will send a CertificateRequest message, asking the client to provide a client certificate.
Step 2: After the user selects the client certificate to be sent, the client will send the client certificate information to the server in the form of a Client Certificate message.
Step 3: The server can only obtain the client’s public key in the certificate after the client certificate is verified, and then start HTTPS encrypted communication.
8.4.2 SSL Client Authentication Using Two-Factor Authentication
In most cases, SSL client authentication does not rely solely on certificates to complete authentication. It is generally combined with form-based authentication (explained later) to form a two-factor authentication (Two-factor authentication) for use. The so-called two-factor authentication means that the authentication process requires not only the password as a factor, but also requires the applicant to provide other information, which is used as another factor and combined with it.
In other words, the first authentication factor, the SSL client certificate, is used to authenticate the client computer, and the other authentication factor, the password, is used to confirm that this is the user’s own behavior.
After passing the two-factor authentication, it can be confirmed that the user is using the correct matching computer to access the server.
8.5 Form-based authentication
The form-based authentication method is not defined in the HTTP protocol. The client sends login information (Credential) to the Web application on the server and authenticates according to the verification result of the login information.
8.5.1 Authentication is mostly based on form authentication
Due to the convenience and security issues in use, BASIC authentication and DIGEST authentication provided by the HTTP protocol standard are rarely used. In addition, although SSL client authentication has a high level of security, it has not yet been popularized due to issues such as introduction and maintenance costs.
8.5.2 Session management and cookie application
The standard specification for form-based authentication has not yet been determined, and cookies are generally used to manage sessions.
Since HTTP is a stateless protocol, the status of a user who has been successfully authenticated before cannot be saved at the protocol level. In other words, state management cannot be achieved, so even when the user continues to visit next time, he cannot be distinguished from other users. So we use cookies to manage sessions to make up for the state management function that does not exist in the HTTP protocol.
Step 1: The client puts login information such as user ID and password into the entity part of the message, usually sending the request to the server using the POST method. At this time, HTTPS communication is used to display the HTML form screen and send the user input data.
Step 2: The server issues a Session ID to identify the user. Identity authentication is performed by verifying the login information sent from the client, and then the user’s authentication status is bound to the Session ID and recorded on the server side.
When returning a response to the client, the Session ID (such as PHPSESSID=028a8c…) is written in the header field Set-Cookie.
You can think of the Session ID as a rank number used to distinguish different users.
However, if the Session ID is stolen by a third party, the other party can pretend to be you and perform malicious operations. Therefore, it is necessary to prevent the Session ID from being stolen or guessed. To achieve this, the Session ID should use a string that is difficult to guess, and the server side also needs to manage the validity period to ensure its security.
In addition, to reduce the damage caused by cross-site scripting attacks (XSS), it is recommended to add the httponly attribute to the cookie in advance.
Step 3: After the client receives the Session ID sent from the server, it will save it locally as a cookie. The next time a request is sent to the server, the browser will automatically send the cookie, so the Session ID is also sent to the server. The server side can identify the user and his authentication status by verifying the received Session ID.
9. HTTP-based function addition protocol
9.1 HTTP-based protocol
When establishing the HTTP standard specification, the drafters mainly wanted to use HTTP as a protocol for transmitting HTML documents. With the development of the times, the use of the Web has become more diverse, such as evolving into online shopping websites, SNS (Social Networking Service), various management tools within enterprises or organizations, and so on.
The functions pursued by these websites can be achieved through Web applications and scripts. Even if these functions have met the needs, the performance may not be optimal, because of the limitations of the HTTP protocol and its own limited performance.
9.2 SPDY to eliminate HTTP bottlenecks
Google released SPDY (taken from SPeeDY, pronounced the same as speedy) in 2010. Its development goal is to solve the performance bottleneck of HTTP and shorten the loading time of Web pages (50%).
SPDY- The ChromiumProjects
http://www.chromium.org/spdy/
9.2.1 HTTP bottlenecks
-
Only one request can be sent on a connection;
- Requests can only be initiated from the client. The client cannot receive instructions other than responses;
- Request / Response headers are sent without compression. The more header information, the greater the delay;
- Sending lengthy headers. Sending the same headers to each other each time causes more waste;
- Data compression format can be selected arbitrarily. Non-compulsory compression is sent;
10. Technology for building web content
10.1 HTML
10.1.1 Web pages are almost entirely built with HTML
Hypertext Markup Language (Hypertext Markup Language) is a markup language developed for sending hypertext on the Web. Hypertext is a document system that can associate information at any location in a document with other information (text or images, etc.), that is, hyperlinked text. Markup language refers to a language used to modify a document by inserting special string tags in a certain part of the document. We call this special string that appears in an HTML document an HTML tag.
10.1.2 Versions of HTML
To this day, there are still many unresolved issues in HTML. Some browsers do not follow the HTML standard implementation, or extend their own tags, which reflects the fact that the HTML standard has not yet been unified.
10.1.3 Design and apply CSS
CSS (Cascading Style Sheets) can specify how to display various elements in HTML and is one of the style sheet standards. Even for the same HTML document, by changing the applied CSS, the appearance of the page seen by the browser will change accordingly. The idea of CSS is to separate the structure and design of a document to achieve the purpose of decoupling.
10.2 Dynamic HTML
10.2.1 Dynamic HTML that makes web pages dynamic
Dynamic HTML is a general term for technologies that use client-side scripting languages to turn static HTML content into dynamic content. News that can be opened with a mouse click, scrollable maps such as Google Maps, etc. use dynamic HTML.
Dynamic HTML technology is to dynamically transform HTML web pages by calling the client-side scripting language JavaScript. The DOM (Document Object Model) can be used to specify HTML elements that are to be dynamically changed.
10.2.2 Easier to control HTML DOM
DOM is an API (Application Programming Interface) used to operate HTML documents and XML documents. Using DOM, you can operate elements in HTML as objects, such as taking out strings in elements, changing the properties of CSS, etc., to change the design of the page.
10.3 Web Applications
10.3.1 Web Applications that Provide Functionality through the Web
Web applications refer to applications that provide functionality through the Web. For example, shopping websites, online banking, SNS, BBS, search engines, and e-learning. There are all kinds of Web applications on the Internet or corporate intranets.
The original mechanism of the Web that applied the HTTP protocol was to return pre-prepared content to requests sent by clients. However, as the Web became more and more popular, this approach alone was no longer sufficient to meet all needs, and it was necessary to introduce the approach of creating HTML content by programs.
Content created by programs like this is called dynamic content, while pre-prepared content is called static content. Web applications act on dynamic content.
10.3.2 CGI that collaborates with Web servers and programs
CGI (Common Gateway Interface) refers to a set of mechanisms that a Web server forwards to a program after receiving a request sent by a client. Under the action of CGI, the program will take corresponding actions to the requested content, such as creating dynamic content such as HTML.
Programs that use CGI are called CGI programs, which are usually written in programming languages such as Perl, PHP, Ruby and C.
10.3.3 Servlet popularized by Java
Servlet1 is a program that can create dynamic content on the server. Servlet is an interface implemented in Java language and is part of enterprise-oriented Java (JavaEE, Java Enterprise Edition).
10.4 Data publishing format and language
10.4.1 Extensible Markup Language
XML (eXtensible Markup Language) is a general-purpose markup language that can be extended according to application goals. It aims to make Internet data sharing easier by using XML.
XML, like HTML, uses tags to form a tree structure, and can customize extension tags.
Reading data from XML documents is simpler than HTML. Since the structure of XML is basically a tree structure divided by tags, it is easier to read data by parsing the XML structure and extracting data elements through the parsing function of the parser.
XML is widely accepted on the Internet because it is easier to reuse data. For example, it can be used to format exchange data between two different applications.
10.4.2 RSS/Atom for publishing updated information
RSS (Realistically Simple Syndication, also called aggregated content) and Atom are both general terms for formats for publishing updated information documents such as news or blog logs. Both use XML.
10.4.3 Lightweight and easy-to-use JSON derived from JavaScript
JSON (JavaScript Object Notation) is a lightweight data markup language based on the object representation of JavaScript (ECMAScript). The data types that can be processed are false/null/true/object/array/number/string, these 7 types.
11. Web attack techniques
11.1 Web attack techniques
The simple HTTP protocol itself does not have security issues, so the protocol itself will hardly become the target of attack. The server and client that apply the HTTP protocol, as well as the Web application running on the server and other resources are the attack targets.
Currently, most attacks from the Internet are directed at Web sites, and most of them take Web applications as attack targets. This chapter mainly explains the attack techniques for Web applications.
11.1.1 HTTP does not have the necessary security functions
Take the SSH protocol used for remote login as an example. SSH has protocol-level authentication and session management functions, while the HTTP protocol does not. In addition, in terms of setting up SSH services, anyone can easily create a service with a high security level, while even if the HTTP server has been set up, if you want to provide a Web application based on the server, in many cases you need to redevelop it.
Therefore, developers need to design and develop authentication and session management functions by themselves to meet the security of Web applications. Self-design means that there will be various implementations. As a result, the security level is not complete, but behind the still-operating Web applications are hidden various security vulnerabilities that can be easily abused by attackers.
11.1.2 Requests can be tampered with on the client
In Web applications, all the contents of HTTP requests received from the browser can be freely changed and tampered with on the client. Therefore, Web applications may receive content that is different from the expected data.
Loading attack code in the HTTP request message can launch an attack on the Web application. The attack code is transmitted through the URL query field or form, HTTP header, Cookie, etc. If there is a security vulnerability in the Web application at this time, the internal information will be stolen or the attacker will get management rights.
11.1.3 Attack modes for web applications
There are two types of attack modes for web applications: active attack and passive attack
- Active attack targeting the server
Active attack refers to an attack mode in which the attacker directly accesses the web application and passes the attack code. Since this mode directly attacks the resources on the server, the attacker needs to be able to access those resources.
Representative attacks in the active attack mode are SQL injection attacks and OS command injection attacks.
- Passive attack targeting the server
Passive attack refers to an attack mode that uses trap strategies to execute attack codes. During a passive attack, the attacker does not directly attack the target web application.
Step 1: The attacker induces the user to trigger the set trap, and the trap will start sending an HTTP request with the embedded attack code.
Step 2: When the user is unknowingly attacked, the user’s browser or email client
will trigger the trap. Step 3: After being attacked, the user’s browser will send an HTTP request containing the attack code to the Web application that is the target of the attack, and run the attack code.
Step 4: After executing the attack code, the Web application with security vulnerabilities will become a springboard for attackers, which may lead to the theft of personal information such as cookies held by users, malicious abuse of user rights in the logged-in state, and other consequences.
Representative attacks in the passive attack mode are cross-site scripting attacks and cross-site request forgery.
11.2 Security vulnerabilities caused by incomplete output value escape
The implementation of security countermeasures for Web applications can be roughly divided into the following two parts:
-
Client-side verification
-
Server-side (Web application-side) verification: input value verification, output value escape
In most cases, JavaScript is used to verify data on the client side. However, it is not suitable to use JavaScript verification as a security countermeasure because data tampering or JavaScript is allowed to be turned off on the client side. Client-side verification is retained only to identify input errors as early as possible and to improve the UI experience.
Input value validation on the web application side may be mistaken for offensive code if it is processed in the web application. Input value validation usually refers to preventive measures such as checking whether it is a numerical value that conforms to the system business logic or checking character encoding.
When outputting data processed by the web application from the database or file system, HTML, email, etc., it is a crucial security strategy to escape the output value. When the output value is not completely escaped, it will trigger the attack code passed in by the attacker and cause damage to the output object.
11.2.1 Cross-site scripting (XSS) attack
Cross-site scripting (XSS) is an attack that runs illegal HTML tags or JavaScript in the browser of a registered user on a web site with security vulnerabilities. The dynamically created HTML part may hide security vulnerabilities. In this way, the attacker writes a script to set a trap, and when the user runs it on his own browser, he will be attacked passively without paying attention.
Cross-site scripting attacks may cause the following effects.
-
Using fake input forms to obtain user personal information.
-
Using scripts to steal the user’s Cookie value, the victim helps the attacker send malicious requests without knowing it.
-
Displaying fake articles or pictures
11.2.2 SQL injection attacks
- SQL injection attacks that execute illegal SQL
SQL injection refers to attacks that run illegal SQL against the database used by Web applications. This security risk may cause great threats and sometimes directly lead to the leakage of personal and confidential information.
Web applications usually use databases. When it is necessary to retrieve, add, delete, and other operations on data in the database table, SQL statements are used to connect to the database for specific operations. If there are omissions in the way SQL statements are called, it is possible to execute illegal SQL statements that are maliciously injected (Injection).
SQL injection attacks may cause the following effects: illegally viewing or tampering with data in the database, circumventing authentication, executing programs related to database server business, etc.
11.2.3 OS Command Injection Attack
OS Command Injection refers to the execution of illegal operating system commands through Web applications to achieve the purpose of the attack. As long as the Shell function can be called, there is a risk of being attacked.
Operating system commands can be called from Web applications through Shell. If there is an omission when calling Shell, the inserted illegal OS command can be executed.
OS command injection attacks can send commands to Shell to start programs from the command line of Windows or Linux operating systems. In other words, various programs installed on the OS can be executed through OS injection attacks.
11.2.4 HTTP Header Injection Attack
HTTP Header Injection refers to an attack in which the attacker inserts the line in the response header field to add any response header or body. It belongs to the passive attack mode.
HTTP header injection attacks may cause the following effects:
- Setting any Cookie information
- Redirecting to any URL
- Displaying any body (HTTP response truncation attack)
11.2.5 Mail header injection attack
Mail header injection refers to the email sending function in a web application. The attacker injects a header into the To or S header of the email.ubject. Using a web site with security vulnerabilities, you can send advertising or virus emails to any email address.
11.2.6 Directory traversal attack
Directory traversal attack refers to an attack that illegally cuts off the directory path of a file directory that is not intended to be made public to achieve the purpose of access. This attack is sometimes also called path traversal attack.
When processing files through a web application, if there is an oversight in the processing of the externally specified file name, the user can use relative paths such as …/ to locate absolute paths such as /etc/passed, so any file or file directory on the server may be accessed. In this way, it is possible to illegally browse, tamper with, or delete files on the web server.
11.2.7 Remote File Inclusion Vulnerability
Remote File Inclusion refers to an attack in which an attacker uses the URL of a specified external server as a dependent file when part of the script content needs to be read from other files, so that the script can run any script after reading it.
This is mainly a security vulnerability in PHP. For PHP include or require, this is a function that can specify the URL of an external server as the file name through settings. However, this function is too dangerous and is disabled by default after PHP5.2.0.
11.3 Security vulnerabilities caused by setting or design defects
11.3.1 Forced Browsing
Forced Browsing security vulnerability refers to browsing files that were originally not voluntarily made public from files placed in the public directory of the Web server.
For files that were originally unwilling to be made public, their URLs will be hidden to ensure security. But once those URLs are known, it means that the files corresponding to the URLs can be browsed. When easily guessed file names or file directory indexes are directly displayed, the URL may be leaked through certain methods.
11.3.2 Improper error message handling
The security vulnerability of incorrect error message handling (Error Handling Vulnerability) refers to the fact that the error message of the Web application contains information useful to the attacker. The main error messages related to Web applications are as follows.
-
Error messages thrown by Web applications
-
Error messages thrown by systems such as databases
11.3.3 Open redirection
Open redirection (Open Redirect) is a function that redirects to any specified URL. The security vulnerability associated with this function is that if the specified redirection URL is to a malicious Web site, the user will be lured to that Web site.
11.4 Security vulnerabilities caused by negligence in session management
Session management is a necessary function for managing user status, but if there is negligence in session management, it will lead to consequences such as the theft of user authentication status.
11.4.1 Session Hijacking
Session Hijacking refers to an attacker obtaining a user’s session ID through some means and illegally using this session ID to disguise as the user to achieve the purpose of the attack.
Web applications with authentication functions use the session management mechanism of session ID as the mainstream way to manage authentication status. The session ID records information such as the client’s cookies, and the server manages the session ID and the authentication status one-to-one.
The following are several ways for attackers to obtain session IDs:
-
Inferring session IDs through informal generation methods
-
Stealing session ID through eavesdropping or XSS attacks
-
Forcibly obtaining session ID through session fixation attacks (Session Fixation)
11.4.2 Session Fixation Attacks
For session hijacking, which uses stealing the target session ID as an active attack method, session fixation attacks force users to use the session ID specified by the attacker, which is a passive attack.
The attacker prepares a trap and first visits the Web site to get the session ID (SID=f5d1278e8109). At this moment, the session ID is still recorded in the (unauthenticated) state on the server. (Steps 1 ~ 2)
The attacker sets a trap to force the user to use the session ID and waits for the user to authenticate with the session ID. Once the user triggers the trap and completes the authentication, the state of the session ID (SID=f5d1278e8109) on the server (user A authenticated) will be recorded. (Step 3)
The attacker estimates that the user has almost triggered the trap and then uses the previous session ID to access the website. Since the session ID is currently in the (user A authenticated) state, the attacker successfully logs in to the website as user A.
11.4.3 Cross-site request forgery
Cross-site request forgeries (CSRF) attack refers to the attacker setting up traps to force the authenticated user to perform unexpected personal information or setting information and other status updates, which is a passive attack.
11.5 Other security vulnerabilities
11.5.1 Password cracking
Two methods of password cracking:
Password trial and error through the network, cracking of encrypted passwords (referring to the situation where the attacker invades the system and obtains encrypted or hashed password data)
- Password trial and error through the network
- Brute force method
Brute force method (also known as brute force cracking method) refers to the exhaustive search of the key space (Keyspace) composed of all key sets. That is, using all feasible candidate passwords to try and error the target password system to break through the verification.
- Dictionary attack
Dictionary attack refers to an attack method that uses candidate passwords collected in advance (stored in a dictionary after various combinations) to enumerate the passwords in the dictionary and try to pass authentication.
Let’s take the example of banks using “4-digit” personal identification codes. Considering that users are more likely to use their birthdays as passwords, they can digitize their birthdays, such as saving 0101~1231 in a dictionary, and try it.
- Cracking encrypted passwords
When saving passwords, Web applications generally do not save them directly in plain text. They use hash functions to hash or add salt to encrypt the passwords to be saved. Even if the attacker uses some means to steal password data, if they want to really use these passwords, they must first use decoding and other means to restore the encrypted passwords to plain text.
11.5.2 Clickjacking
Clickjacking refers to the use of transparent buttons or links to create traps and cover them on Web pages. Then, the user is tricked into clicking on the link to access the content without knowing it. This behavior is also called UI Redressing.
The web page that has been set up with traps may not appear to have any problems on the surface, but it has already embedded a link that the user wants to click. When the user clicks on the transparent button, he actually clicks on the iframe page of the element with the specified transparent attribute.
11.5.3 DoS attack
DoS attack (Denial of Service attack) is an attack that stops the running service. Sometimes it is also called service stop attack or denial of service attack. The targets of DoS attack are not limited to web sites, but also include network devices and servers.
There are mainly two types of DoS attacks:
-
Concentrated use of access requests to cause resource overload. When the resources are exhausted, the service industry is actually stopped;
-
Stop the service by attacking security vulnerabilities.
Among them, the DoS attack that concentrates on access requests is simply to send a large number of legitimate requests. It is difficult for the server to distinguish between normal requests and attack requests, so it is difficult to prevent DoS attacks.